Metrics¶
The main goal of the HintEval framework is to allow users to evaluate their own hints or generated hints. It enables users to assess the quality of hints and easily compare their hint generation pipelines with state-of-the-art studies. Currently, five evaluation metrics are available for assessing the quality of hints: Relevance, Readability, Convergence, Familiarity, and Answer Leakage.
The metrics Relevance, Readability, Convergence, and Familiarity were introduced by Mozafari et al. 2024, and Answer Leakage was introduced by Mozafari et al. 2024.
HintEval extends these evaluation metrics by offering various methods for each metric, accommodating different user needs based on their available computational resources.
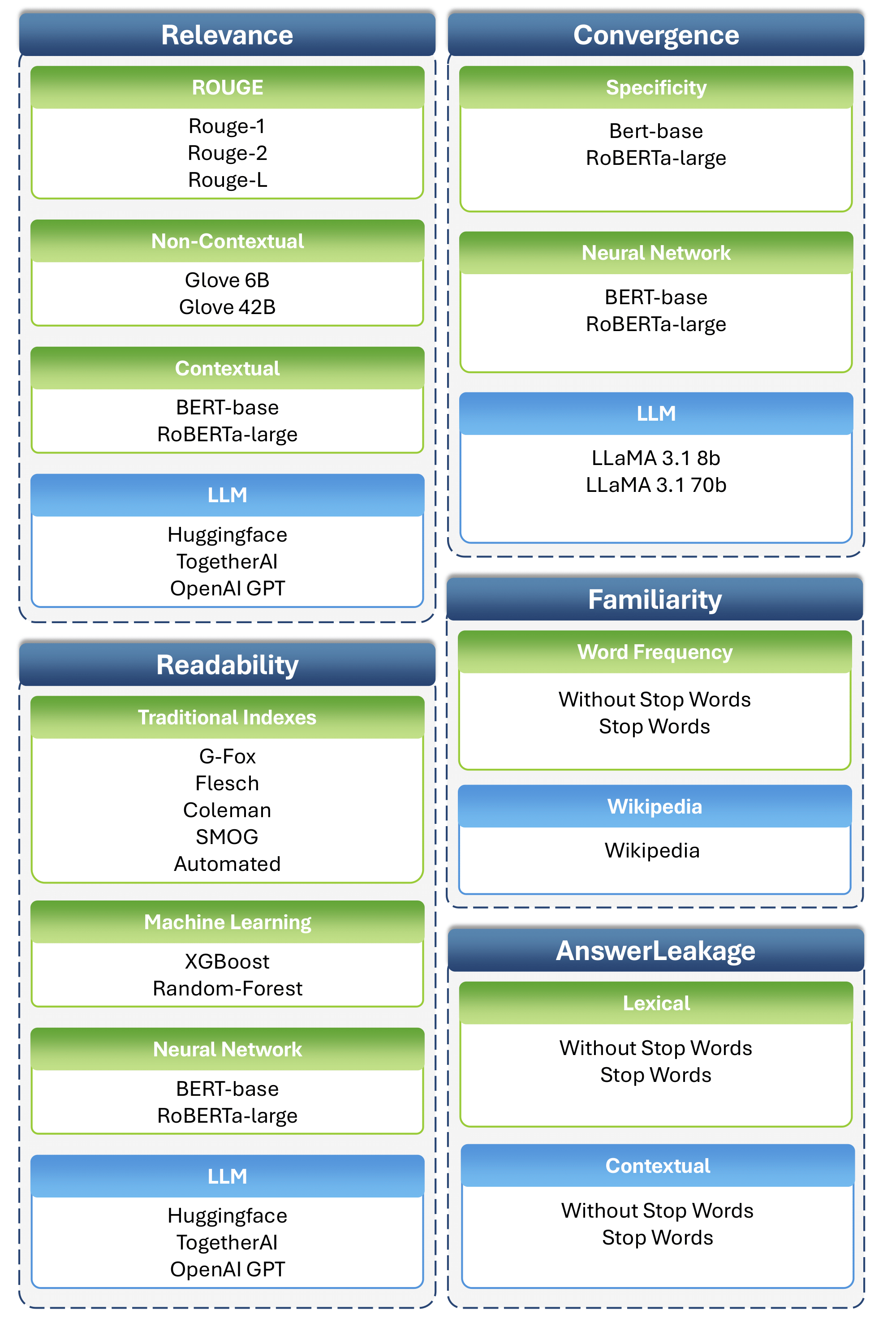
Available Evaluation Metrics¶
Explore the available evaluation metrics:
How to compute the relevance between questions and hints.
How to compute the readability of questions and hints.
How to compute the convergence of hints.
How to compute the familiarity of questions, hints, and answers.
How to compute the answer leakage of hints.
Common Attributes¶
Evaluating sentences or datasets using large language models (LLMs) can be computationally intensive and time-consuming. Errors like GPU memory overflow or API connection failures can interrupt the evaluation process, making it impractical to start over from scratch. To address these challenges, the HintEval framework offers two key features: checkpoints and a memory_release function.
Checkpoints¶
To ensure that progress is not lost during evaluations, you can enable the checkpoint feature. This saves the current state at regular intervals, so in case of errors, you can resume from the last checkpoint rather than restarting the entire evaluation. You can control how frequently checkpoints are saved using the checkpoint_step parameter, which defines the number of steps between each save.
For example, in the code below, we evaluate readability for sentences using the meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo model with a batch size of 5. We enable the checkpoint feature and set it to save progress after every step, ensuring evaluations can resume from the last successful step:
Warning
To enable and use checkpointing, customize the directory where checkpoints are stored. For more information on customization, refer to Customizations.
from hinteval.evaluation.readability import LlmBased
api_key = 'your_api_key'
base_url = 'https://api.together.xyz/v1'
llm = LlmBased(model_name='meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo', api_key=api_key, base_url=base_url,
checkpoint=True, batch_size=5, checkpoint_step=1)
Releasing Memory¶
Another common issue when evaluating large datasets with LLMs, especially on local systems, is GPU memory overflow. To prevent crashes due to memory constraints, HintEval provides a release_memory function. After completing an evaluation, you can call this function to free up GPU resources. This is particularly helpful when running multiple evaluation tasks or models in sequence.
Here’s how you can release memory after an evaluation:
llm.release_memory()
Progress Tracking¶
For monitoring the progress of evaluations, HintEval supports the tqdm library, which creates real-time progress bars. By enabling the enable_tqdm parameter, you can track the progress of evaluations as they are processed.
Here’s an example that combines checkpointing, memory release, and progress tracking:
from hinteval.cores import Question, Hint
from hinteval.evaluation.readability import LlmBased
llm = LlmBased(model_name='meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo',
api_key='your_api_key', checkpoint=True, checkpoint_step=1, enable_tqdm=True)
sentence_1 = Question('What is the capital of Austria?')
sentence_2 = Hint('This city, once home to Mozart and Beethoven, is the capital of Austria.')
sentences = [sentence_1, sentence_2]
llm.evaluate(sentences)
classes = [sent.metrics['readability-llm-meta-llama_Meta-Llama-3.1-70B-Instruct-Turbo'].metadata['description'] for sent in sentences]
print(classes)
llm.release_memory()
Example progress output:
Evaluating readability metric using meta-llama_Meta-Llama-3.1-70B-Instruct-Turbo: 100%|██████████| 1/1 [00:17<00:00, 17.19s/it]
['beginner', 'beginner']
With these features, you can efficiently manage the computational challenges of evaluating datasets using LLMs. Progress can be saved incrementally, memory usage is optimized, and you can track evaluation progress in real-time.